6. What do you mean by document vectors?
Answer: Document Vector contains the frequency of each word of the vocabulary in a particular document.
In document vector vocabulary is written in the top row. Now, for each word in the document, if it matches with the vocabulary, put a 1 under it. If the same word appears again, increment the previous value by 1. And if the word does not occur in that document, put a 0 under it.
7. What is TFIDF? Write its formula.
Answer: Term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.
The number of times a word appears in a document divided by the total number of words in the document. Every document has its own term frequency.
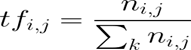
8. Which words in a corpus have the highest values and which ones have the least?
Answer: Stop words like – and, this, is, the, etc. have highest values in a corpus. But these words do not talk about the corpus at all. Hence, these are termed as stopwords and are mostly removed at the pre-processing stage only.
Rare or valuable words occur the least but add the most importance to the corpus. Hence, when we look at the text, we take frequent and rare words into consideration.
9. Does the vocabulary of a corpus remain the same before and after text normalization? Why?
Answer: No, the vocabulary of a corpus does not remain the same before and after text normalization. Reasons are –
- In normalization the text is normalized through various steps and is lowered to minimum vocabulary since the machine does not require grammatically correct statements but the essence of it.
- In normalization Stop words, Special Characters and Numbers are removed.
- In stemming the affixes of words are removed and the words are converted to their base form.
So, after normalization, we get the reduced vocabulary.
10. What is the significance of converting the text into a common case?
Answer: In Text Normalization, we undergo several steps to normalize the text to a lower level. After the removal of stop words, we convert the whole text into a similar case, preferably lower case. This ensures that the case sensitivity of the machine does not consider same words as different just because of different cases.
11.Mention some applications of Natural Language Processing.
Answer: Natural Language Processing Applications-
- Sentiment Analysis.
- Chatbots & Virtual Assistants.
- Text Classification.
- Text Extraction.
- Machine Translation
- Text Summarization
- Market Intelligence
- Auto-Correct
12. What is the need for text normalization in NLP?
Answer: Since we all know that the language of computers is Numerical, the very first step that comes to our mind is to convert our language to numbers.
This conversion takes a few steps to happen. The first step to it is Text Normalization. Since human languages are complex, we need to first of all simplify them in order to make sure that understanding becomes possible. Text Normalization helps in cleaning up the textual data in such a way that it comes down to a level where its complexity is lower than the actual data.
13. Explain the concept of Bag of Words.
Answer: Bag of Words is a Natural Language Processing model which helps in extracting features out of the text which can be helpful in machine learning algorithms. In the bag of words, we get the occurrences of each word and construct the vocabulary for the corpus.
Bag of Words just creates a set of vectors containing the count of word occurrences in the document (reviews). Bag of Words vectors is easy to interpret.
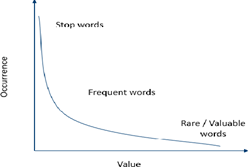
14. Explain the relationship between the occurrence and value of a word.
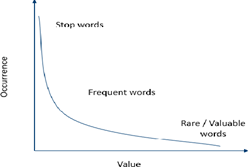
Answer: As shown in the graph, the occurrence and value of a word are inversely proportional. The words which occur most (like stop words) have negligible value. As the occurrence of words drops, the value of such words rises. These words are termed as rare or valuable words. These words occur the least but add the most value to the corpus.
15. What are the applications of TFIDF?
Answer: TFIDF is commonly used in the Natural Language Processing domain. Some of its applications are:
• Document Classification – Helps in classifying the type and genre of a document.
• Topic Modelling – It helps in predicting the topic for a corpus.
• Information Retrieval System – To extract the important information out of a corpus.
• Stop word filtering – Helps in removing the unnecessary words out of a text body.
16. What are stop words? Explain with the help of examples.
Answer: “Stop words” are the most common words in a language like “the”, “a”, “on”, “is”, “all”. These words do not carry important meaning and are usually removed from texts. It is possible to remove stop words using Natural Language Toolkit (NLTK), a suite of libraries and programs for symbolic and statistical natural language processing.
17. Differentiate between Human Language and Computer Language.
Answer: Humans communicate through language which we process all the time. Our brain keeps on processing the sounds that it hears around itself and tries to make sense out of them all the time.
On the other hand, the computer understands the language of numbers. Everything that is sent to the machine has to be converted to numbers. And while typing, if a single mistake is made, the computer throws an error and does not process that part. The communications made by the machines are very basic and simple.
Four 04 Mark Questions
1. Create a document vector table for the given corpus:
- Document 1: We are going to Mumbai
- Document 2: Mumbai is a famous place.
- Document 3: We are going to a famous place.
- Document 4: I am famous in Mumbai.
| We | Are | going | to | Mumbai | is | a | famous | place | I | am | in |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 |
2. Classify each of the images according to how well the model’s output matches the data samples:
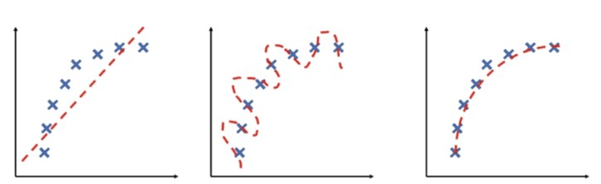
Here, the red dashed line is model’s output while the blue crosses are actual data samples.
Answer:
● The model’s output does not match the true function at all. Hence the model is said to be under fitting and its accuracy is lower.
● In the second case, model performance is trying to cover all the data samples even if they are out of alignment to the true function. This model is said to be over fitting and this too has a lower accuracy
● In the third one, the model’s performance matches well with the true function which states that the model has optimum accuracy and the model is called a perfect fit.
3. Explain how AI can play a role in sentiment analysis of human beings?
Answer: The goal of sentiment analysis is to identify sentiment among several posts or even in the same post where emotion is not always explicitly expressed.
Companies use Natural Language Processing applications, such as sentiment analysis, to identify opinions and sentiment online to help them understand what customers think about their products and services (i.e., “I love the new iPhone” and, a few lines later “But sometimes it doesn’t work well” where the person is still talking about the iPhone) and overall *
Beyond determining simple polarity, sentiment analysis understands sentiment in context to help better understand what’s behind an expressed opinion, which can be extremely relevant in understanding and driving purchasing decisions.

By Anjeev Kr Singh – Computer Science Educator
Published on : September 19, 2022 | Updated on : February 9, 2023
About the Author







